
The Ghost Node Pattern
Defending Real-Time Graphs from Data Swamps

In my last post, I broke down the latency metrics of my streaming graph pipeline. Hitting a sub-15ms P95 ingestion time felt like a massive win for the architecture, until I actually looked at the topology of what I was ingesting. I had successfully built a high-speed pipe, but I quickly realized I was using it to build a data swamp.
When building standard data pipelines over the last 18 years, the primary goal has almost always been throughput: get the data from Source A to Destination B as fast as possible. But when building an AI Context Engine, a hyper-eager pipeline is actively dangerous.
If you connect a firehose of enterprise events directly to Memgraph, the pipeline’s eagerness becomes its biggest liability. Imagine a sales rep fat-fingering a Salesforce update for “Microsft” instead of “Microsoft.” A naive streaming pipeline instantly writes a brand new, isolated node into the graph for that typo. Your AI agent now has fractured context and is reasoning over hallucinated entities.
It’s the Bootstrap Problem: how do you start building a graph from a firehose of noisy events without instantly turning it into a hallucination factory?
The Architecture: Building the GhostNodeManager
To solve this, I had to fundamentally change how data moves in Sprint 14.
Before this sprint, the ingestion scripts (sec_ingestion.py and synthetic_crm.py) were taking events and throwing them straight over the wall into the resolution engine, and then directly into Memgraph. I needed a bouncer at the door.
I built the GhostNodeManager into the routing layer (pipelines/routing.py). Instead of acting as a pure passthrough, it uses Pathway’s stateful stream processing capabilities to hold events in a temporary memory buffer. These buffered events are called “Ghost Nodes” because they exist in the stream’s state, but they are strictly forbidden from materializing in the graph database yet.
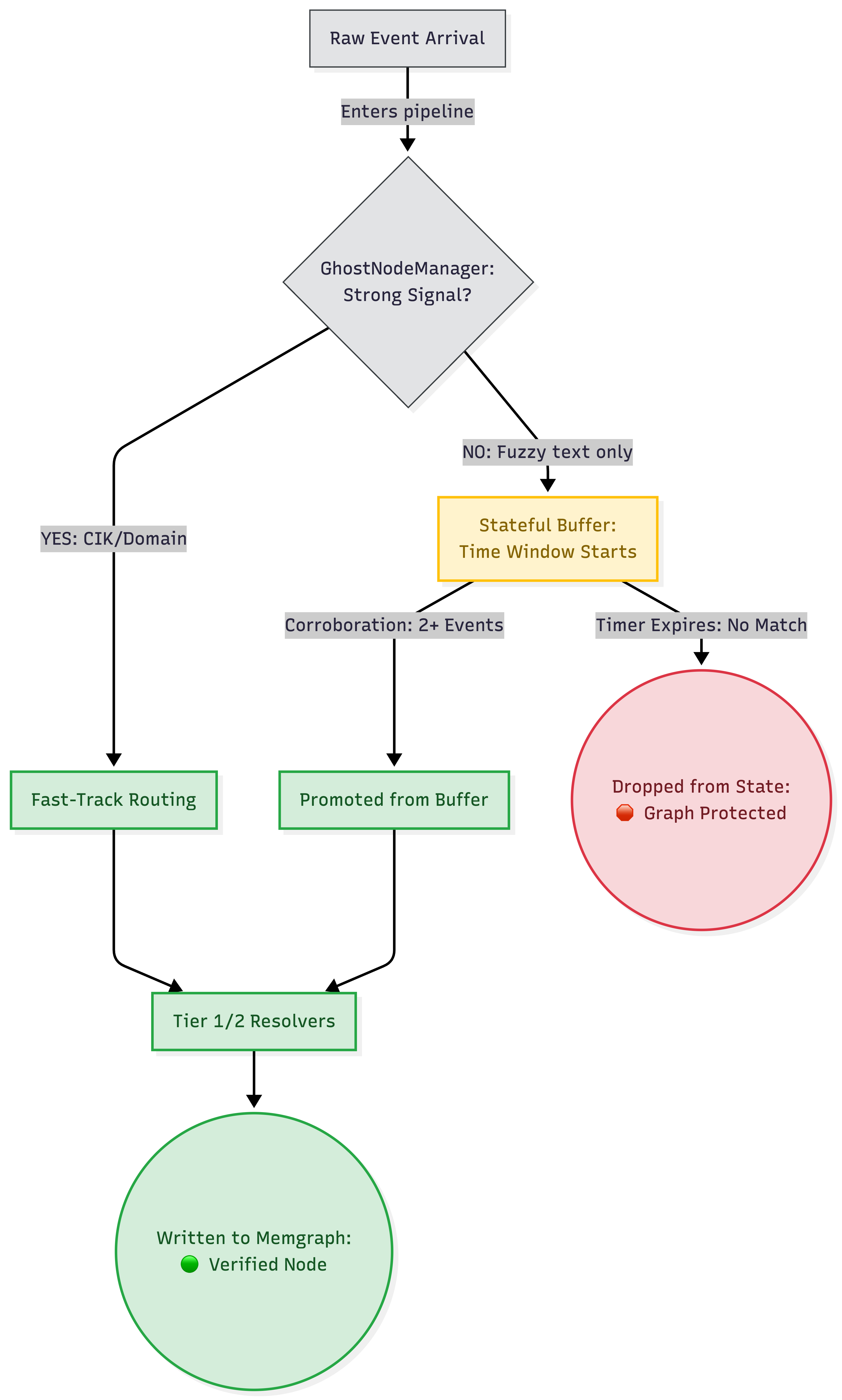
The Code Logic: Eagerness vs. Skepticism
When a new AccountEvent arrives, the GhostNodeManager runs it through an evidence checklist before allowing it to touch the graph. Here is exactly what the logic is doing under the hood:
The “Strong Signal” Fast-Track: The code checks the event for definitive identifiers. Does this event have a verified
cik_number, an exactcompany_domain, or a hardaccount_id? If Yes: The event skips the waiting room. It is instantly promoted, sent through the resolvers, and written to Memgraph.The “Corroboration” Waiting Room: If the event only has a fuzzy text string (like
company_name = "Globel Corp"), the code parks it in the stateful buffer and starts a time window. It waits to see if another distinct event arrives with that same fuzzy name. If 2+ events accumulate: The code decides this isn’t a one-off typo; it’s a real (if poorly named) entity. The threshold is met, and the batch of events is flushed out of the buffer and promoted to Memgraph. If no other events arrive: The ghost node eventually expires and is dropped entirely, saving the graph from permanent pollution.
Skepticism at the Ingestion Layer
The biggest lesson from this architectural pivot is shifting the mindset from standard data engineering to context engineering.
In traditional pipelines, the goal is pure throughput. But when we are feeding an LLM, real-time context is completely useless if the underlying graph is flooded with noise. The only way an LLM agent can reason accurately is if the graph it queries has been aggressively defended against bad data at the ingestion layer.
We need to teach our context engineering pipelines to be skeptical rather than mere dumb pipes.
See you next week.
The repository: github.com/snudurupati/autonomous-knowledge-fabric
Sreeram Nudurupati | LinkedIn
AI Architect | Building the Autonomous Knowledge Fabric in public: 90 days, no hand-waving.