
Weights vs. Maps: The Myth of the ‘Magic’ AI
Why Your Fine-Tuning Failed the Multi-Hop Test (and How to Fix It)

This is the conclusion of an 8-week series: “From Data Engineer to AI Architect.” We’ve explored the shift from traditional data engineering to designing agentic systems built on stochastic LLM compute, where tokens, latency, and probabilistic behavior are first-class constraints. Along the way, we progressed from enforcing structure and determinism to building increasingly sophisticated RAG pipelines, orchestration layers, and multi-hop graph reasoning systems with explainability built in. We also examined Continued Pre-Training (CPT) and the practical realities of building knowledge graphs on local infrastructure.
Today, we declare the winner of our capstone: GraphRAG.
Executive Summary:
For the last couple of weeks, we have been running a high-stakes contextual “Bake-Off.” We pitted the reigning champion, a model fine-tuned using Continuous Pre-training (CPT) on specialized clinical data (the “Parametric Contender”), against a baseline model augmented by a structured Graph Substrate (the “Semantic Contender”).
The goal was to solve the “Missing Middle” in enterprise AI; the point where an LLM is fluent but factually untraceable. While CPT provided fluency, GraphRAG provided fidelity. The moment of truth arrived in our final “Multi-Hop” query.
The Test: “In our clinical records, what role does the ‘forearm’ play in measuring glucose uptake for hypertensive subjects?”
The Results:
Contender A (Week 7 CPT):
"Data not found in substrate."Contender B (Week 8 GraphRAG):
"The forearm is the site where glucose uptake was measured..."
🕵️ Post-Mortem: Why Weights Forget What Maps Remember
At first glance, this “failure” of fine-tuning is confusing. The model was trained on that exact data in Week 7. As an AI Architect, you must understand the plumbing of memory.
1. Technical Deep Dive: The Parametric Fog vs. Explicit Edges
When you train a model like Llama-3 (CPT), you are using Gradient Descent on massive amounts of text. Backpropagation smooths out information, prioritizing frequent patterns.
The relationship between “Forearm” and “Glucose Uptake” is extremely rare (low-frequency) across 3,500 abstracts. It exists as a fragile statistical ghost in the 8 billion parameters. When queried, that detail gets “drowned out” by more common patterns. Weights forget the rare fact.
In contrast, our Semantic Substrate (Memgraph) materialized that rare fact as an explicit edge: (Forearm)-[MENTIONS]-(Abstract_123)-[MENTIONS]-(Glucose_Uptake). When the query hits the graph, we walk that path with 100% fidelity. Maps remember the exact path.
2. Knowledge Graph Advantage: Explainability
This is the largest business win for GraphRAG.
CPT (The Black Box): When it answers, it gives you a fluent prediction based on a memory it cannot cite. If a clinician asks, “Which abstract justified this claim?” the CPT model is a dead end. In an enterprise setting, this is a liability.
GraphRAG (The Glass Box): The response is a synthesis of extracted documents. It explicitly provides Source IDs (e.g.,
[Abstract ID: abs_001]). The model has provided an auditable decision path. This is explainable AI.
🏗️ The AI Architect’s Comparison Matrix
We have visualized the core metrics of our two contenders below. Since Substack doesn’t handle tables, we have generated an infographic performance matrix.
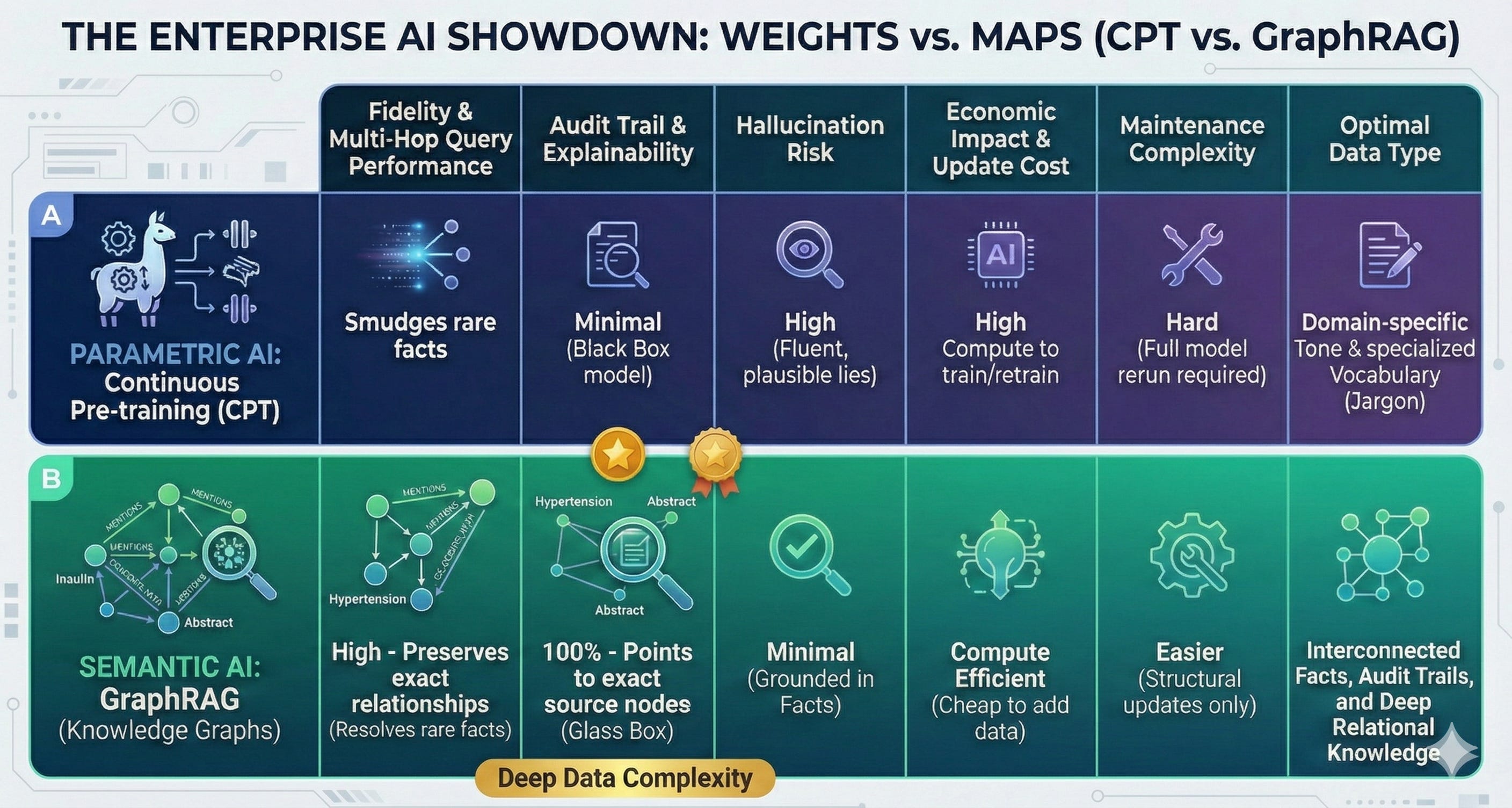
3. Business and Economic Impact
CPT (The Week 7 Model): The economic story is high upfront compute to train (even with LoRA). Updates require retuning, another costly compute job.
GraphRAG (The Week 8 Substrate): The economic story is low update cost. Adding new data is computationally cheap (adding nodes to Memgraph). The primary cost is in the initial ingestion pipeline and Entity Resolution.
When to Use Continuous Pre-training (CPT)
Despite the clear win in fact fidelity, CPT is not dead. As an AI Architect, you must understand its unique value:
Specialized Vocabulary: When your data uses dense acronyms, proprietary codes, or unique clinical jargon, CPT “seeds” the base model’s tokenizer with this dialect.
Domain Tone & Style: CPT can adapt Llama-3 to a specific format. A good example is transforming complex medical research into concise patient-facing summaries.
Low-Resource Languages: CPT is the standard for introducing entirely new languages to a base LLM.
Final Verdict: Architecture over Weights
The "Missing Middle" isn't solved by making models bigger or training them longer. It's solved by Context Engineering and Knowledge Graphs are the Key. By building a Graph Substrate, we moved from an AI that "remembers" to an AI that "researches." CPT gives you fluency, but GraphRAG gives you fidelity.
We have completed the transformation from Data Engineer to AI Architect. We have moved from raw data ingestion to fine-tuning Llama-3, and finally to building a queryable contextual nervous system. The substrate is built. Now, it's time to let the agents run.
This concludes this 8-week series, but stay tuned for my next series, where I combine two of my favorite topics, streaming and context engineering, to build a real-time context engine.
Get the full code here in the repo: https://github.com/snudurupati/agentic-ai-architect