
Curing AI Hallucinations
Addressing AI’s Missing Middle via Continued Pre-training

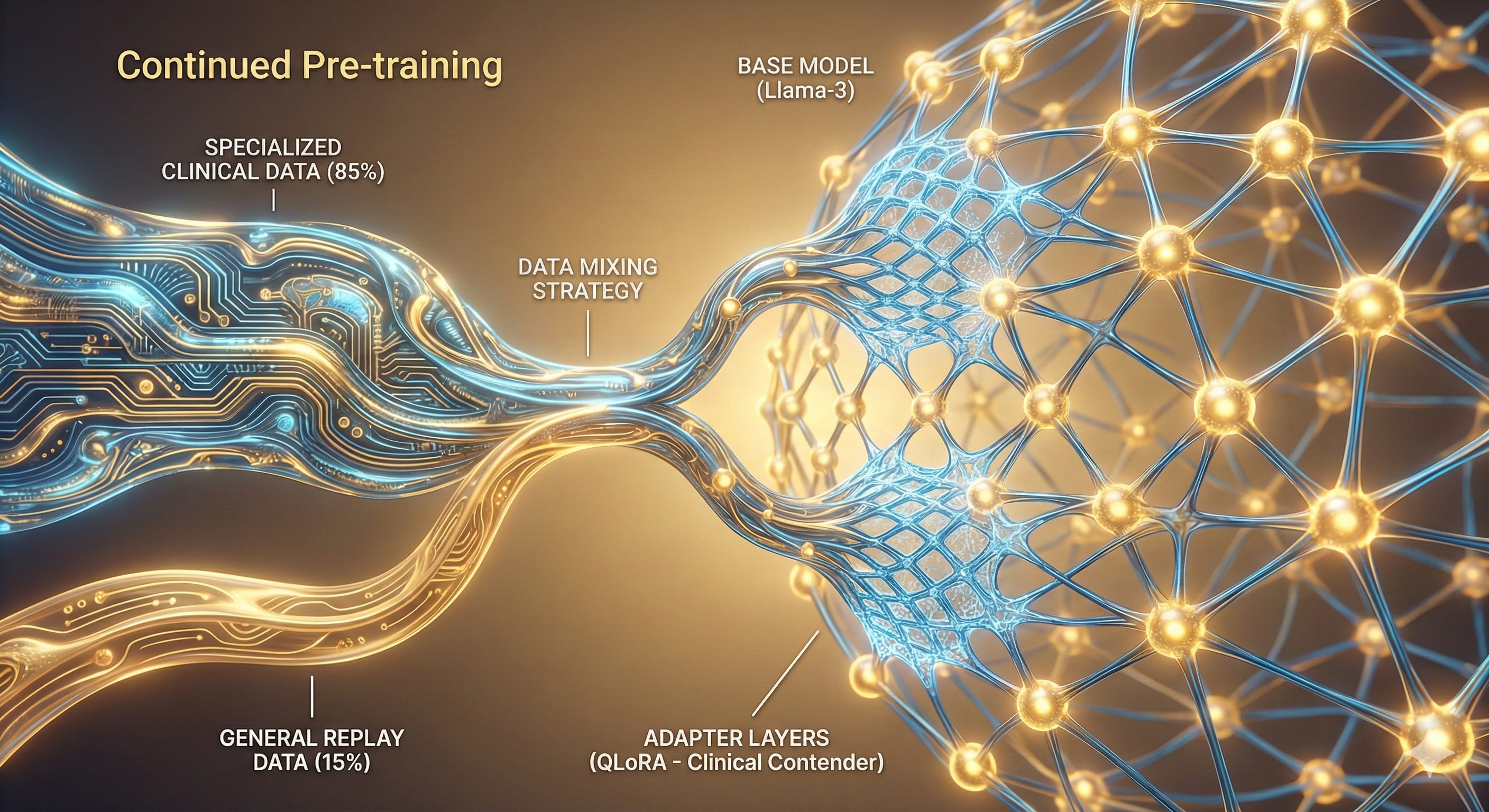
In the enterprise, the biggest barrier to deploying reliable AI agents isn’t a lack of compute; it’s the “Missing Middle.”
General-purpose LLMs are brilliant at reasoning, but they often lack the specific, high-fidelity context of a company’s internal world. When an agent is asked a question that requires deep domain knowledge it hasn’t “seen,” it fills the gap with plausible-sounding nonsense. This is the root of hallucinations.
To solve this, enterprises generally have two architectural options:
Continued Pre-training (CPT): Modifying the model’s Parametric Layer (its “brain”) so that specialized knowledge is baked directly into the weights.
Knowledge Graphs (GraphRAG): Creating a Semantic Layer (a “library”) where relationships and facts are stored externally and retrieved as needed.
This week, as part of a multi-week “Bake-Off,” I am putting Continued Pre-training to the test. I’ve built a specialized “Clinical Contender” to see if altering the model’s internal weights can bridge this context gap. Next week, we will implement a Knowledge Graph solution, concluding the series with a final side-by-side comparison.
Phase 1: What is Continued Pre-training?
Continued Pre-training is the process of taking a “commodity” model (like Llama-3) and extending its self-supervised learning phase on a specialized, private corpus. Unlike fine-tuning, which teaches a model how to act, CPT teaches a model a new language.
Why Enterprises Consider this Path:
Vocabulary Priming: Teaching the model technical acronyms and jargon that don’t exist in general web crawls.
Conceptual Density: Increasing the model’s internal “intuition” for domain-specific relationships.
Data Sovereignty: Building a model that is natively “aware” of your proprietary data distribution.
The Experiment: 500 Iterations on an M4 Mac
To “walk the walk,” I performed a QLoRA-based run on my MacBook Air M4 (24GB RAM) using the MLX framework.
The Methodology:
To maintain architectural stability and prevent Catastrophic Forgetting, I engineered a “Substrate Mix” for the training data:
85% Domain-Specific Technical Data: High-fidelity abstracts and technical documentation.
15% General Replay Data: A slice of WikiText-2 to act as a linguistic anchor.
The Performance Metrics:
Training Iterations: 500
Peak Memory Usage: 9.456 GB (Successfully leveraging the M4’s Unified Memory).
Throughput: ~68 Tokens/sec (Optimized for fanless thermal profiles).
✅ Findings: The Impact on Parametric Memory
The experiment yielded a specialized adapters.safetensors file. After 500 iterations, the Train Loss dropped by approximately 19%, resulting in several notable shifts:
Increased Technical Precision: The model moved from generalities to technical standards. It refined definitions of complex acronyms and processes from vague “web-search” results to precise, industry-standard definitions.
Structural Awareness: It demonstrated a more detailed understanding of internal mechanics and structural relationships within the specialized dataset.
Linguistic Trade-offs: The model became highly technical, but the process highlighted a drift in the “Assistant” persona, resulting in a loss of conversational formatting (repetitive
<|eot_id|>tokens) as the weights favored the raw technical substrate over instruction-following.
The Business Impact Matrix: CPT vs. The Enterprise Reality
For VPs and CXOs, the choice to pursue Continued Pre-training isn’t just a technical one; it’s a question of Total Cost of Ownership and Intellectual Property Portability.
🏗️ Infrastructure: High-Density GPU Clusters (A100/H100) or High-Memory Apple Silicon
Business Impact: High CapEx/OpEx. Requires significant upfront investment or aggressive cloud-compute burn.
⏱️ Time-to-Value: 4–12 Weeks
Business Impact: Agility Risk. The process involves extensive data prep, training, and safety testing. If the base model (e.g., Llama 3) is updated, you may be forced to re-train from scratch.
👥 Staffing: Requires ML Scientists & Specialized Engineers
Business Impact: Hiring Gap. High “specialist” dependency. These roles carry $250k+ price tags and represent a significant “flight risk” in a competitive market.
🔍 Auditability: “Black Box” Weights
Business Impact: Compliance Risk. It is difficult to trace the origin of a specific output back to a specific data point, creating barriers for regulated industries like Health or Finance.
1. The Human Capital Factor: Upskilling vs. Specialist Hiring
A CPT strategy requires a “Pit Crew” of PhDs and ML Scientists to manage weight decay and prevent the model from “losing its mind” (Catastrophic Forgetting). Conversely, leveraging existing Data Engineering talent to build Knowledge Graphs allows for a faster upskilling path. Data Engineers are already experts in schemas; transitioning them to “AI Architects” is often more sustainable than competing for scarce ML Research talent.
2. Operational Stability: The “Llama-4” Problem
The most significant business risk for CPT is Sunk Cost. If you spend $200k in compute to bake your proprietary data into Llama-3, and a more efficient Llama-4 is released next month, your investment is non-transferable. You are back at the starting line. A Knowledge Graph approach ensures State Sovereignty; your data lives in your database, not in the model weights, making it LLM-agnostic.
Architectural State of Play
We now have a fully realized Clinical Contender, a model whose weights have been specialized for a technical domain. This represents our first successful approach to solving the “Missing Middle.”
Get the full code here in the repo: https://github.com/snudurupati/agentic-ai-architect/tree/main/07_continued_pre_training
Next Week: The Showdown. We implement the second option, a Knowledge Graph (GraphRAG) architecture. Once both are built, we will perform a final “Bake-Off” to determine which approach provides the best balance of accuracy, cost, and operational flexibility.