
AI is great at finding words. It’s time to help it reason.
From Semantic Similarity to Structural Reasoning: A Data Engineer’s Guide to the Multi-Model Future of AI.

Week 4: Data Engineer to AI Architect Series
For 18 years, SQL has been my bread and butter. I’ve lived through the rise of NoSQL, the Hadoop era, and the Cloud Data Warehouse boom. But as I transition into an AI Solutions Engineer role, I’ve realized a hard truth: The tools that helped us store the world’s data are failing to help us think with it. I’ve noticed a sobering reality: despite the hype, the success rate for AI projects is surprisingly low. MIT research shows nearly 40% of companies with high AI investment see no significant business gains.
The primary culprit? The Context Problem.
Beyond Semantic Similarity: The Need for Context
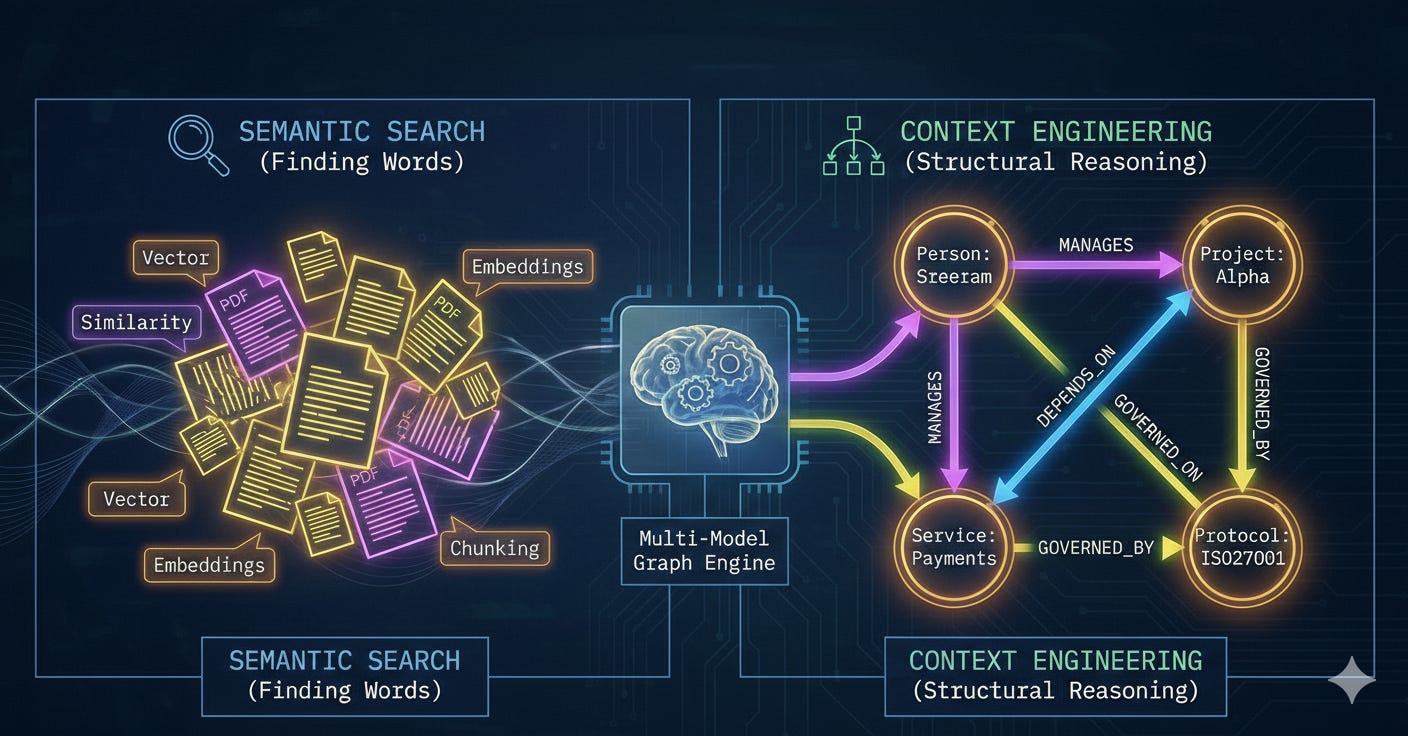
We’ve been told that Vector Databases are the “brain” of GenAI. In reality, they are more like a sophisticated index of “semantic vibes.” They measure the mathematical distance between strings of text, but they don’t understand the logical relationship between facts.
Simply vectorizing PDFs and storing chunks in a vector database doesn’t solve the underlying problem. A vector database might find two separate documents that mention “Project Alpha”, but it lacks the inherent logic to know that the Project Manager listed in a 2024 HR directory is the same person responsible for the Security Breach mentioned in a 2026 server log. Without the capability to traverse these connections, your retrieval system fails to capture the full picture, leading to the “I don’t know” loop or, worse, confident hallucinations.
The “Structuring Crisis”: Why Multi-Model is the Solution
The hardest part of AI isn’t retrieval, it’s the mess that comes before it. This is what I call the Structuring Crisis. Teams spend months manually writing scripts to parse 200-page PDF case files, breaking them into chunks, and attempting to extract metadata. Even after that labor-intensive work, they face a dilemma: Should the data live in a vector store for search? A relational system for filtering? Or a graph for relationships?
This “architectural tax”, the need to move data between three specialized databases, is where most AI projects struggle. This is precisely why Multi-Model Databases are the solution to the structuring crisis.
A Multi-Model approach solves the crisis by eliminating the need to choose:
Flexible Ingestion: You can ingest the “mess” as raw Documents (JSON) without a rigid schema, preserving every scrap of metadata from emails to log files.
Contextual Linking: You can then define Edges (Relationships) between those documents as you discover them, turning your document store into a Knowledge Graph on the fly.
Integrated Retrieval: When it’s time for the AI to “think,” you don’t have to hop between systems. You can perform a Vector Search to find the starting point and immediately execute a Graph Traversal to find the context, all in a single query.
The symbiosis is simple: AI helps clean and connect the unstructured data, and the Multi-Model database provides a single, unified home for the resulting “Reasoning Backbone.” You aren’t just storing data anymore; you are building a system where the document, the vector, and the relationship live together.
The Bakeoff: Vector Search vs. GraphRAG
This week, I ran a “Glass Box” experiment in my lab. I loaded a small network into ArangoDB, representing a lead architect (me), a project (Project Alpha), and a security protocol (ISO 27001).
👉 GitHub Repo: Data Engineer to AI Architect - Week 4
Then I asked: “What security constraints are linked to Sreeram’s work?”
Vector RAG Answer: “I don’t know.”
The Failure: The vector engine found the chunk about “Sreeram” and the chunk about “Project Alpha,” but it couldn’t “see” the relationship to the “ISO27001” document three degrees away. They were semantically similar but logically disconnected.
GraphRAG Answer: “Sreeram’s work is governed by ISO27001, which mandates hardware-level encryption for the payment services used in Project Alpha.”
The Success: The system performed a Deep Traversal. It followed the logical edges from Person → Project → Service → Protocol.
Why ArangoDB? (A Small Disclosure)
Now, full transparency: I recently joined the team at Arango. But my choice of tool here isn’t just a matter of professional alignment; it’s about solving the “Architectural Tax.”
In a typical AI stack, you’d have to sync data between a Document store, a Vector DB, and a Graph DB. That is a data engineering nightmare. I chose ArangoDB because it is Multi-Model.
It handles document-style lookups, deep graph-style traversals, and native vector search with one query language. In the GenAI era, the baseline requirement is a database that lets you retrieve everything at once without moving data between three different systems.
The Future: Context Engineering
If you’ve spent the last few years mastering prompt engineering and vector indexing, those skills are your foundation, but they aren’t the ceiling. The next evolution of AI will be built on Context Engineering.
Graphs will be the backbone of this movement. They are the way to provide AI with the structural reasoning it needs to stop hallucinating and start performing. Context engineering isn’t just about the words; it’s about the connections between them.
“A relational database can store your knowledge. A graph database lets you think with it.”
Next Week: We’ll move into Agentic Workflows. Showing how an AI agent can “self-correct” by querying the graph when it hits a dead end.
References: